曲突徙薪(きょくとつししん)第8号
GPTを理解する 〜大規模言語モデル(LLM)とは?〜
先月に続いて、言語生成AIの代表技術ともいえるGPT(Generative Pre-trained Transformer)の内容について、なるべく平易に理解する試みを進めていきます。先月はトランスフォーマー(Transformer)についてお話ししましたので、今月は、GPTのもう一つのポイントである事前学習(Pre-trained)の具体的な内容について説明したいと思います。
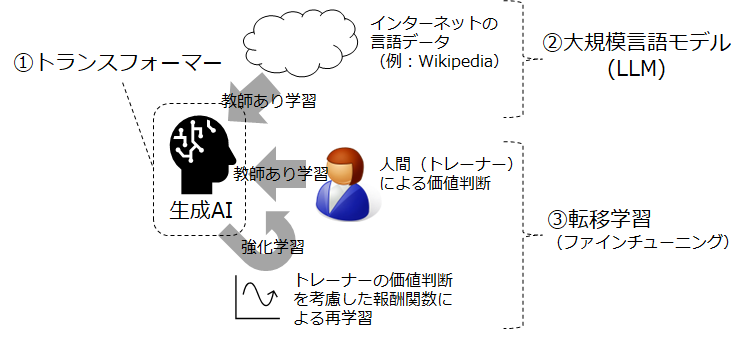
上の図は、言語生成AIを実現する学習部分の概要を整理したものです。前回説明した①のトランスフォーマーは、生成AIというコンピューターシステムの実体をなす、ニューラルネットワークにおけるパラメータの具体的な計算方法(アルゴリズム)のことでした。
これに対して②の大規模言語モデル(large language model, LLM)は、膨大な量の言語のデータを数値化したうえで、その特徴を抽出する技術です。大量データを取り扱うハードウェア面の技術革新のほか、言語データの特徴を表現するために必要となるベクトル化の技術や、前回説明したトランスフォーマーを用いた学習プロセスが含まれます。また③の転移学習は、人間をトレーナーとする教師あり学習と、教師あり学習をもとに構築した報酬関数を使った強化学習を組み合わせることで、より自然な受け答えができるようにLLMを鍛え上げる役割を担っています。
私たちユーザーは、②と③の学習を済ませたものを実際には活用していますが、今回は、このうち「事前学習」と呼ばれることの多い②のLLMについて、詳しく内容を紹介します。