曲突徙薪(きょくとつししん)第7号
アテンションとは?
エンベッド処理と位置エンコーディングによって加工された入力情報には、次にエンコーダでの処理を通じて「文脈」に関する情報を与えられます。エンコーダは、アテンション層とフィードフォワード層という2つの処理に分かれており、アテンション論文の事例では、2つの処理を6度積み重ねる階層構造を採用しています。入力情報となる複数のベクトルに対して、ベクトルの掛け算や足し算の処理を繰り返し、最終的には512次元のベクトルを出力しています。このエンコーダ処理のことを、狭義の「トランスフォーマー」と呼ぶことがあります。
トランスフォーマーがそれまでの技術と異なる最大のポイントが、次の「アテンション」という処理にあります。これについては、アテンション論文の共同著者の一人であるAidan N. Gomez氏の所属するリサーチ会社Cohere社による解説が参考になりますので、それに沿って概要を説明します。
アテンションは日本語では「注意処理」などと訳すところもありますが、それだけではまったく処理のイメージが湧かないものと思います。概念的な理解のためには、とりあえず日本語訳は忘れたほうがよさそうです。アテンションがおこなっていることは、大まかに言うと、文脈に応じて文字列の中の単語同士の距離を修正する処理です。この単語同士の距離とは、先述のエンベッド処理で説明した、単語同士のベクトル空間上の距離のことです。先ほどの例でいうと、「おじいさん」(2,2)は、同じ名詞の「むかしむかし」(1,1)の近くにありますが、助詞の「に」(9,9)からは遠く離れている、そのようなイメージになります。この単語間の距離を文脈に応じて変化させることで、同じ意味の文字列がなるべく同じようなベクトルの組み合わせになるように調整するのが、アテンションの役割になります。
さて、異なる単語同士の距離であれば、単語の使用事例などを参考に単語間の距離を特定することもできそうですが、もう一つ問題になるのが、同じ単語であってもその意味が文脈によって微妙に、時には大きく異なるケースです。アテンションではこの問題を、ある単語のベクトルを、他の単語のベクトルとの組み合わせで表現することでクリアしていきます。次の例を考えてみます。
1.巨人が中日に勝つ
2.知性の巨人が逝く
2つの例文はいずれも「巨人」という単語を含んでいますが、1はプロ野球の球団を、2は権威ある人物のことをそれぞれあらわしており、2つの例文における「巨人」の意味合いは大きく異なります。アテンションでは、周りの単語との関係によってこの2つを区別するために、巨人という単語を「巨人A」と「巨人B」という異なる単語に分けた上で、「巨人A」のベクトルを「中日」に、「巨人B」を「知性」に近づけることで、両者を異なる単語として認識します。単純な式であらわすと以下のようになります。
巨人A = 0.8×巨人 + 0.2×中日
巨人B = 0.9×巨人 + 0.1×知性
次にそれぞれの文字列の「中日」と「知性」も、それぞれ「巨人」に近づけます。
中日A = 0.2×巨人 + 0.8×中日
知性B = 0.1×巨人 + 0.9×知性
これらの処理を通じて、入力された文字列と順序のベクトル、そしてそれらに対する重み付け(パラメータともいいます)が、アテンションの前後で次のように変化します。
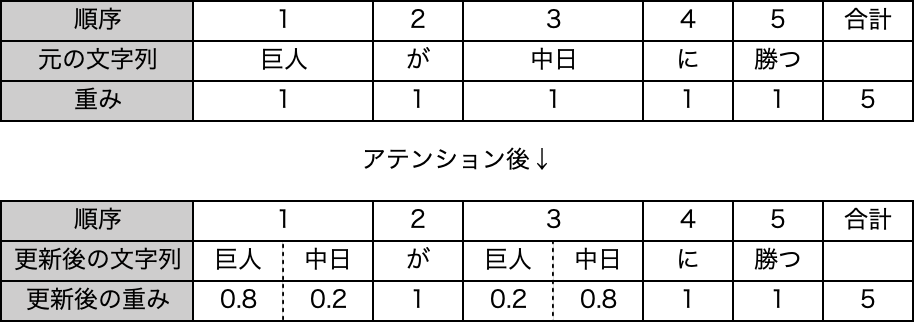
アテンションの前後で重み付けの合計は変わりませんが、文字列と順序、重み付けの組み合わせが、アテンション処理の前後で変化していることがわかります。こうして、私たちヒトが「文脈」と呼ぶ、単語の順序や組み合わせによる文字列全体の微妙な意味の違いが、ベクトルの中に情報として取り込まれます。このようにアテンションは、文字列に応じて「注意」すべき文字列を特定し、重み付けを変えることで文脈を表現する処理といえます。なお、ここで説明したのは”Self-Attention”(自己アテンション)と呼ばれる単純なアテンションの一つで、アテンション論文の中では、より微妙な文脈の差異を表現できる”Multi-Head Attention”(多頭型アテンション)が採用されています。