曲突徙薪(きょくとつししん)第7号
トランスフォーマーのモデル構造
次の図表はトランスフォーマーのモデル構造をあらわしたものです。左下に入力データ、右上に出力結果(確率)があり、その途中で複数の工程が、ときに繰り返しをはさみながら順番に進められていく構造になっています。元になったアテンション論文の図は、さまざまな論文やWebサイトにて参照されているのをご覧になった方も多いと思いますが、ここではオリジナルの図を単純化して日本語で示しています。ここではもう少し詳しく、図表が示すトランスフォーマーの各ブロックの順にしたがって、その内容を見てみることにしましょう。
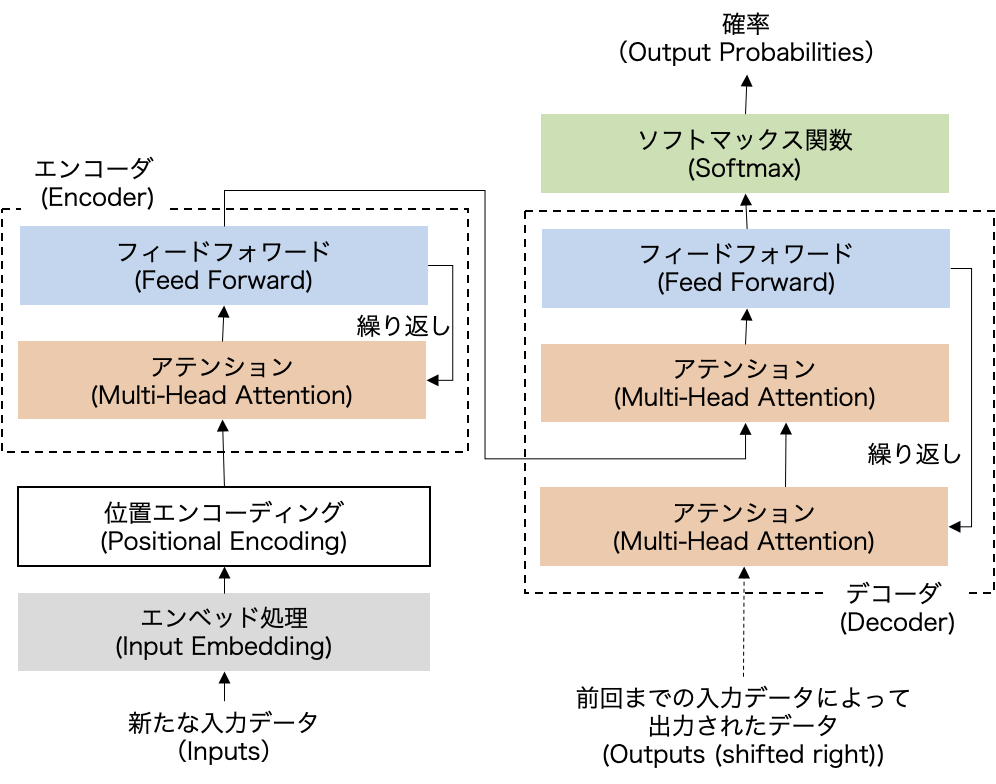
(出所:“Attention Is All You Need”より筆者改)
エンベッド処理とエンコーディング
最初に来るのが「新たな入力データ」です。ChatGPTもそうですが、元々のトランスフォーマーも、入力データとして「文字列」を想定しています。ただし入力データはこのあとの工程で数値化されるので、いまではトランスフォーマーの入力データとしては、文字列に限らず、画像や音声といった非構造化データ全般が対象とされています。
エンベッド処理(Input Embedding)では、文字列を数値の組み合わせに置き換える「ベクトル化」をおこないます。エンベッド処理によって、入力された文字列は、たとえば「むかしむかし」はx=1、y=1、「ある」はx=5、y=3のように、2つの数値のペアに変換されます。これを図にあらわすと図表1.2のようになります。意味や使い方の近い単語同士が、何となく近い場所にあるのが伝わるでしょうか?
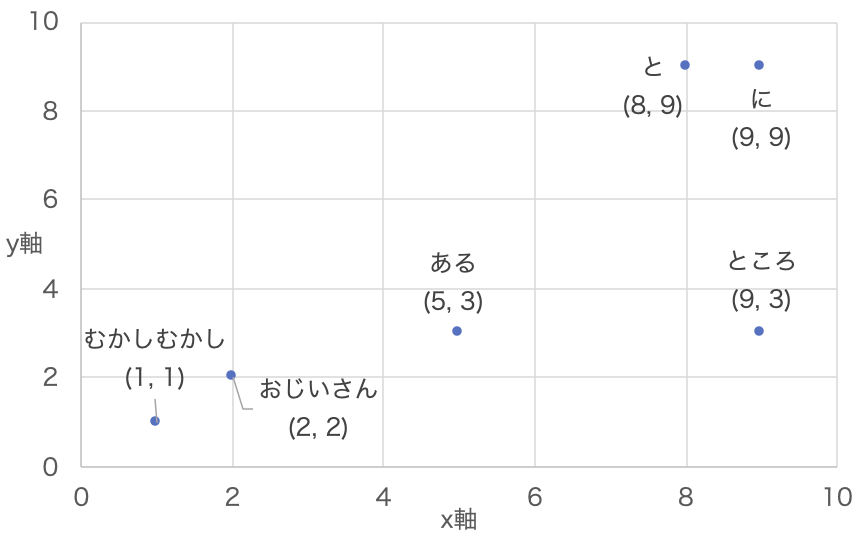
ここではわかりやすく2次元配列(xとyだけであらわせるベクトル)で示していますが、実際には4,096次元など、途方もない規模の多次元空間にて単語が数値化されます。そしてこの空間では、単語同士の距離が意味や使い方の違いをあらわします。このことはあとの処理で重要な意味を持ってきます。なお、数値化された入力情報のことをトークン(token)などと呼ぶことがあります。
位置エンコーディング(Positional Encoding)では、文字列に順序の情報を加えます。たとえば「巨人が中日に勝った」と「中日が巨人に勝った」という2つの文字列を比較すると、出てくる単語はすべて同じですが、順序が違うことで意味は180度異なります。文字列の意味を正しくとらえるためには、単語の順序、つまり位置に関する情報を用意する必要があり、これが位置エンコーディングです。具体的に言うと、エンベッド処理で得られた単語ごとのベクトルに対して、「むかしむかし」は1、「おじいさん」は5、といった形で位置を示す情報が付与されます。エンベッド処理と位置エンコーディングの2つの処理によって、ベクトル化された入力情報に単語と順序に関するすべての情報が付与され、ひとかたまりの入力情報に対して唯一のベクトルの組み合わせが割り当てられます。